Job Market Paper / Submitted to CoRL 2026
ReCoVLA: VLM-Guided Reward Compilation for Failure Recovery in Vision-Language-Action Policies
We collect failure states in simulation, use an external VLM and a reward compiler to ground residual RL rewards, and deploy the trained residual recovery policy zero-shot on a real robot.
Problem
Base VLA policies can struggle after execution enters rare or off-distribution failure states.
Approach
Simulation rollouts expose failure states, which are grounded into residual RL rewards by an external VLM and reward compiler.
Outcome
The trained residual policy recovers from similar physical failure states without additional real-world training.
Overview Video
Supplementary video summary
This video summarizes the failure collection, VLM-guided reward compilation, residual RL training, and zero-shot recovery pipeline.
ReCoVLA supplementary video
A compact overview of how simulated failure states are used to ground residual rewards and transfer recovery behavior to the physical robot.
Method Overview
Failure-conditioned reward compilation for residual VLA recovery
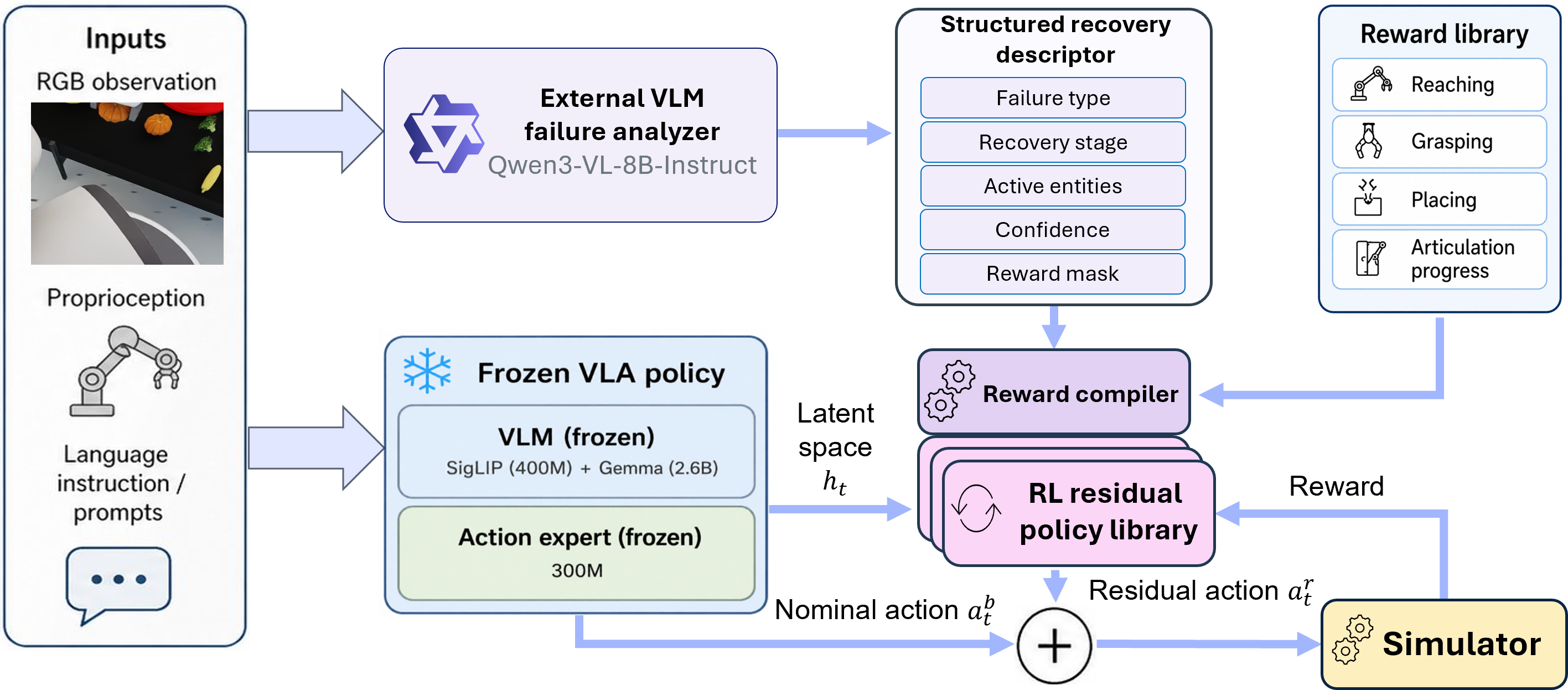
The base VLA policy provides a high-dimensional action proposal. Our residual policy observes VLA features and predicts corrective commands over a compact base-and-torso action subspace, leaving the remaining action dimensions unchanged.
Simulation rollouts are used to collect states where the base VLA policy fails or becomes unreliable. For each observed failure type, the external VLM produces a structured descriptor that the reward compiler turns into a grounded residual RL reward. The resulting residual policy is trained in simulation and then evaluated zero-shot on the physical robot.
Performance
Residual recovery improves simulation, real-robot, and OOD performance
We evaluate success rate and Q-score, both reported in [0, 1] with higher values better. The tables below highlight the main averages, the in-distribution task-level ablation, and transfer to the Behavior-1K Challenge setting.
Main failure-recovery averages
Average over three tasks. Each entry reports success rate / Q-score. M1 is the fine-tuned base VLA without recovery, and M4 is our stage-gated VLM reward compiler with residual RL.
| Setting | M1: no recovery | M4: ReCoVLA | Gain |
|---|---|---|---|
| Simulation | 0.37 / 0.56 | 0.67 / 0.83 | +0.30 / +0.27 |
| Physical robot | 0.27 / 0.40 | 0.62 / 0.75 | +0.35 / +0.35 |
| OOD physical robot | 0.10 / 0.22 | 0.53 / 0.65 | +0.43 / +0.43 |
In-distribution ablation results
Simulation and physical robot task results over 20 trials per method and task. M2 uses a task-level residual reward, M3 uses equal-weight failure rewards, M5 is OpenVLA without recovery, and M6 applies our recovery method to OpenVLA.
| Setting | Task | M1 | M2 | M3 | M4 ours | M5 | M6 |
|---|---|---|---|---|---|---|---|
| Simulation | Average | 0.37 / 0.56 | 0.40 / 0.55 | 0.48 / 0.63 | 0.67 / 0.83 | 0.23 / 0.33 | 0.45 / 0.55 |
| Physical robot | Average | 0.27 / 0.40 | 0.27 / 0.40 | 0.40 / 0.51 | 0.62 / 0.75 | 0.15 / 0.25 | 0.35 / 0.42 |
| Simulation | Sorting vegetables | 0.30 / 0.48 | 0.20 / 0.28 | 0.45 / 0.55 | 0.65 / 0.82 | 0.20 / 0.30 | 0.45 / 0.52 |
| Simulation | Picking up trash cans | 0.55 / 0.67 | 0.70 / 0.79 | 0.60 / 0.71 | 0.75 / 0.88 | 0.40 / 0.45 | 0.60 / 0.68 |
| Simulation | Organizing toolbox | 0.25 / 0.54 | 0.30 / 0.59 | 0.40 / 0.64 | 0.60 / 0.78 | 0.10 / 0.23 | 0.30 / 0.45 |
| Physical robot | Sorting vegetables | 0.25 / 0.36 | 0.10 / 0.20 | 0.45 / 0.50 | 0.60 / 0.72 | 0.10 / 0.20 | 0.40 / 0.48 |
| Physical robot | Picking up trash cans | 0.45 / 0.54 | 0.55 / 0.63 | 0.45 / 0.53 | 0.75 / 0.83 | 0.35 / 0.40 | 0.50 / 0.56 |
| Physical robot | Organizing toolbox | 0.10 / 0.30 | 0.15 / 0.38 | 0.30 / 0.49 | 0.50 / 0.69 | 0.00 / 0.15 | 0.15 / 0.23 |
Additional recovery baselines
Simulation comparison against recent recovery or VLA+RL baselines, evaluated over 20 trials per task.
| Task | Method | Success | Q-score |
|---|---|---|---|
| Average | ReCoVLA | 0.67 | 0.83 |
| Average | RLinf | 0.12 | 0.19 |
| Average | RACER | 0.43 | 0.60 |
Behavior-1K Challenge transfer
Test results on the Behavior-1K Challenge using a different simulated robot platform. Each task uses 20 trials.
| Task | Method | Success | Q-score |
|---|---|---|---|
| Sorting vegetables | ReCoVLA | 0.20 | 0.51 |
| Sorting vegetables | OpenPI Comet | 0.05 | 0.26 |
| Bringing in wood | ReCoVLA | 0.65 | 0.79 |
| Bringing in wood | OpenPI Comet | 0.50 | 0.62 |
| Preparing a lunch box | ReCoVLA | 0.25 | 0.49 |
| Preparing a lunch box | OpenPI Comet | 0.10 | 0.33 |
| Average | ReCoVLA | 0.37 | 0.60 |
| Average | OpenPI Comet | 0.22 | 0.40 |
Simulation Failure Collection
Collecting failure states for reward grounding
These simulation videos show the failure-state collection stage: the base VLA policy encounters states such as misplaced objects, fallen objects, or incomplete interactions. These collected states are passed to the external VLM and reward compiler to produce residual RL training rewards.
Successful task structure
Expert demonstrations provide successful task context. We compare failure rollouts against this structure to identify what recovery should accomplish.
Head view: misplaced broccoli
Simulation failure state where broccoli is misplaced and requires recovery.
Head view: fallen soda can
Simulation failure state where the soda can has fallen on the table.
Head view: unclosed lid
Simulation failure state where the lid remains unclosed after execution.
Wrist view: misplaced broccoli
Companion wrist view used by the VLM and reward compiler.
Wrist view: fallen soda can
Companion wrist view for grounding the fallen-object failure.
Wrist view: unclosed lid
Companion wrist view for grounding the incomplete lid-closing failure.
Physical Recovery
Zero-shot recovery demonstrations
After residual training in simulation, the learned recovery policy is deployed zero-shot. The videos below show the policy recovering from failure states similar to those collected during the simulation reward-grounding stage.
Misplaced broccoli recovery
Shown at 10x speed. The residual policy repositions the robot to recover from a misplaced broccoli state and continue the placement behavior.
Fallen soda can recovery
Shown at 5x speed. The residual policy recovers from the fallen-can failure state and guides the robot back toward successful object handling.
Unclosed lid recovery
Shown at 8x speed. The residual policy adjusts the gripper pose and completes lid closing after the base VLA policy leaves the container unclosed.
OOD Stress Tests
Recovery under object substitutions and changed geometry
These sped-up clips show the physical robot under out-of-distribution changes that preserve the task structure but alter object appearance or geometry. The residual recovery policy remains conditioned on the detected failure state and helps the base VLA return to a solvable execution state.
Sorting vegetables OOD
Shown at 16x speed. The sorting task uses an object substitution, replacing pumpkin with tomato, while preserving the same receptacle-placement objective.
Soda-can disposal OOD
Shown at 8x speed. The disposal task uses a taller soda can, testing whether the recovery policy can handle changed object geometry after failure.
Organizing toolbox OOD
Shown at 14x speed. The toolbox task replaces the cable with tape, stressing recovery in a contact-rich setting with a visually and physically different object.
Behavior-1K Challenge
Recovery demonstrations on a different robot platform
These 10x videos show ReCoVLA on three Behavior-1K Challenge tasks from the appendix. The setting uses a different simulated robot platform and tests whether failure-conditioned reward compilation transfers beyond the Fetch tabletop recovery tasks.
Sorting vegetables on the table
Shown at 10x speed. The robot recovers from dropped or misplaced vegetables, re-grasps the failed object, and returns it to the intended receptacle.
Bringing in wood
Shown at 10x speed. The recovery behavior handles a constrained bimanual manipulation failure, including adjusting the carried wood and continuing through the door-opening stage.
Preparing a lunch box
Shown at 10x speed. The policy recovers from placement errors while picking up food items and placing them into the lunch box.
Resources
Supplementary material
Open paper
Open supplementary PDF
This page collects the overview video, method figure, performance tables,
real-robot recovery clips, OOD stress tests, and Behavior-1K demonstrations.